신규 프로젝트를 진행하며, 더 이상 온프레미스 서버에서 관리하지 않고, 클라우드 컴퓨팅, 컨테이너 환경을 선택했다.
고가용성과 오토 스케일링, 또한 여러 컨테이너 환경을 첫 운영함에 있어서 쿠버네티스 , 도커 스웜, AWS ECS를 고려했다.
쿠버네티스와 도커 스웜 역시 강력한 컨테이너 오케스트레이션 도구였지만, AWS ECS 클러스터 인프라에서 배포 컴퓨팅 환경으로
서버리스 컴퓨팅 형태인 Fargate를 사용할 수 있다는 장점으로 인해 AWS ECS를 선택, 그에 맞는 인프라를 구축하기로 하였다.
Route53
Amazon Route 53은 가용성과 확장성이 뛰어난 DNS 웹 서비스이며, 사용자 요청을
AWS 또는 온프레미스에서 실행되는 인터넷 애플리케이션에 연결한다.
위 그림과 같이 DNS로 도메인을 별도 구입하여 해당 도메인의 라우팅 경로를 VPC내에 있는 로드 밸런서의 ARN으로 연결 시켜주었다.
Application Load Balancer(ALB)
해당 로드 밸런서의 리스너는 두 가지 경우를 만들어 주었다.
HTTP:80
HTTP 프로토콜의 기본 포트인 80으로 접근 시, HTTPS:443(프로토콜:포트)를 리다이렉션 대상으로 삼아 주었다.
이로써 http 프로토콜로 접속해도 보안 접속이 가능해졌다.
HTTPS:443
리스너 규칙으로 접근하려는 호스트의 헤더에 api.도메인.com가 붙여져있다면 백엔드 대상 그룹으로 라우팅 경로를 지정 .
그 외의 요청은 프론트엔드 대상 그룹으로 라우팅 경로를 지정
로드밸런서의 대상 그룹은 ECS에서 테스크 서비스가 배포되는 시점에서 선택을 할 수 있다.
예를 들어, 백엔드 서비스가 포함된 컨테이너 배포시, 기존에 생성한 로드 밸런서의 대상 그룹 A를 지정해준다면,
배포된 컨테이너 서비스가 자동으로 로드밸런서의 백엔드 대상 그룹으로 지정돼, 라우팅을 수신 할 수 있게 된다.
추가로 트래픽 분산 알고리즘과, 각 대상 그룹에 등록된 서비스의 가중치 지정이 가능하다.
ECS Cluster
서버 자원에 대한 인력 리소스를 줄이기 위해, (ECS를 선택한 이유인) Fargate 컴퓨팅 유형으로 클러스터를 생성해주었고,
해당 클러스터에서 각각 프론트엔드 서비스 , 백엔드 서비스를 배포 하였다.
테스크 정의
테스크 정의의 규격을 vCPU 2, 메모리를 16GB로 리소스를 한정하고,
오토 스케일링 규칙을 해당 테스크가 로드밸런서의 트래픽 량에 따라
최소 3개, 최대 6개까지 유지 될 수 있도록 하여 트래픽 급증에 대비하여 유연하게 서비스를 운영할 수 있게 하였다.
cpu 아키텍처는 X86_64로 설정하였으며, 이는 곧 후에 기술하게 될 GitActions의 도커 이미지 빌드 아키텍처와 맞춰주기 위함이다.
또한 서비스 배포 옵션을 상단의 사진과 같이 최소 실행 작업 비율을 100% , 최대 실행 작업 비율을 200%로 하여
롤링 업데이트 방식으로 무중단 배포를 할 수 있었다.
(본래는 블루/그린 배포 방식으로 하려 했으나, 또 다른 서버 자원의 비용을 감내해야 했기 때문에 배포 속도가 좀 느리더라도
롤링 업데이트 방식을 채택했다..흑)
해당 테스크 스케줄러가 각 서비스 배포 서브넷은 로드 밸런서가 위치한 서브넷과 동일하게 맞춰 주었으며,
로드밸런서도 미리 만들어둔 것으로 지정해주었다. -> 이 로드밸런서의 트래픽 량에 따라 테스크 실행 갯수가 조절이 된다.
GitActions를 통한 배포 자동화
배포 자동화를 구축하기 위해, 방법을 모색하던 중 이미 GitActions 배포 템플릿에서 ECS 배포용 yaml 템플릿이 있어
해당 yml 파일을 입맛에 맞게 커스텀 해주었다.
각 블록을 살펴보자
name: Deploy to Amazon ECS
on:
pull_request_target:
types:
- closed
# 이 옵션을 통해 사용자가 직접 Actions를 통해 워크플로우 실행이 가능 !
workflow_dispatch:
env:
AWS_REGION: ap-northeast-2 # set this to your preferred AWS region, e.g. us-west-1
ECR_REPOSITORY: # set this to your Amazon ECR repository name
ECS_SERVICE: # set this to your Amazon ECS service name
ECS_CLUSTER: # set this to your Amazon ECS cluster name
ECS_TASK_DEFINITION: # set this to the path to your Amazon ECS task definition
# file, e.g. .aws/task-definition.json
CONTAINER_NAME: backend # set this to the name of the container in the
name 블록은 워크 플로우 이름
on
PR이 머지 됐을 경우에만 배포가 될 수 있도록 설정.
workflow_dispatch
위에서 워크 플로우 배포를 실행 하기 위하여 반드시 PR을 머지시켰어야만 했는데,
이를 생략하고 바로 실행할 수 있게 하기 위해 해당 옵션을 지정해주었다.
env
배포할 서비스 리전, 도커 이미지 프라이빗 레포지토리 ARN, ECS 서비스 이름, ECS 클러스터 이름, ECS 테스크 정의 경로, 배포할 컨테이너 이름을 지정해주었다.
# 워크 플로우 종료 후, 배포 결과를 슬렉으로 알리기 위해 필요한 권한 설정
permissions:
contents: read
actions: read
jobs:
deploy:
if: |
# 풀리퀘스트 머지시에만 job 실행
github.event.pull_request.merged == true &&
# 레포지토리가 fork된 레포지토리가 아닌, 원본 레포지토리일 경우에만
github.repository == ${{ secretes.REPOSITORY_NAME }} &&
github.event.pull_request.base.ref == 'main'
# job 이름 설정
name: Deploy
# job 실행 환경 설정
runs-on: ubuntu-latest
# 배포 환경
environment: production
steps:
- name: Checkout
uses: actions/checkout@v3
# GitActions에 ECS 서비스 배포 권한 및 ECR에 푸쉬 할 수 있는 권한을 가진
# IAM 유저의 액세스 키와, 시크릿 키 설정을 해준다.
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
# 도커 이미지 빌드 시, 필요한 환경변수는 이미 .gitignore로 제외 되었기 때문에
# 이미지 빌드 전, repository Secrets에 애플리케이션 환경 변수를 저장 후 생성해준다.
- name: make application.yml
if: contains(github.ref, 'main')
run: |
cd ./src/main/resources
touch ./application.yml
echo "${{ secrets.ENVIRONMENT_MAIN }}" > ./application.yml
shell: bash
# 프로젝트 루트 경로의 도커파일에 맞게 이미지 빌드 후, ECR에 푸쉬
- name: Build, tag, and push image to Amazon ECR
id: build-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
'''
도커 이미지 빌드 명령어
도커 이미지 ECR 푸쉬 명령어
'''
# 배포될 테스크 정의 파일 경로 지정
- name: Fill in the new image ID in the Amazon ECS task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@v1
with:
task-definition: ${{ env.ECS_TASK_DEFINITION }}
container-name: ${{ env.CONTAINER_NAME }}
image: ${{ steps.build-image.outputs.image }}
# ECS 테스크 정의 배포
- name: Deploy Amazon ECS task definition
uses: aws-actions/amazon-ecs-deploy-task-definition@v1
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: ${{ env.ECS_SERVICE }}
cluster: ${{ env.ECS_CLUSTER }}
# 배포한 서비스가 상태가 확인될 때 까지 대기
wait-for-service-stability: true
# 배포 결과 슬렉 전송
- name: action-slack
uses: 8398a7/action-slack@v3
with:
# 프론트엔드와 백엔드 레포지토리가 분리 되어있기 때문에 따로 설정해준다.
status: ${{ job.status }}
author_name: 백엔드 배포 결과
fields: repo,message,commit,author,action,eventName,workflow
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }} # required
if: always()
위와 같이 yml 파일로 배포 자동화를 설정 후에 배포 자동화가 무사히 잘 이뤄진 것 까지 확인해보았다.
문제점
GitActions에서는 배포 때 마다, 매번 새로운 실행환경을 생성하니 도커 빌드의 캐시를 제대로 활용하지 못하고 있었음
이는 곧 매 배포 시마다 새롭게 이미지 빌드를 하며 배포 시간이 늘어남
해결방안 : GitActions에서의 도커 이미지 레이어 캐시 활용
레이어 캐시를 사용하는 step을 추가해주면 같은 레이어를 다시 빌드하는데 드는 시간을 줄일 수 잇다.
구성 가능한 컴퓨팅 자원(예: 컴퓨터 네트워크, 데이터 베이스, 서버, 스토리지, 애플리케이션, 서비스)에 대해 어디서나 접근 할 수 있는, 주문형 접근(on-demand availability of computer system resources)을 가능케하는 모델이며 최소한의 관리 노력으로 빠르게 예비 및 릴리스를 가능케 한다.
2. 스케일 아웃(Scale-out)과 스케일 업(Scale-up)의 차이를 설명하라.
인프라 업그레이드를 위한 두 가지 방안으로,
스케일 업은 기존 서버의 자원 및 성능을 보다 업그레이드 하는 것을 의미한다.
단 적인 예로, 자원 및 성능 증강을 목적으로 서버의 디스크를 직접 구매해 추가하거나 , 동일한 방법으로 CPU나 메모리를 추가로 장착해 업그레이드 시킨다.
스케일 아웃
기존 서버만으로 요청이나 성능의 한계가 도달했을 때, 서버를 더 증설해 처리할 수 있는 양을 더 늘리거나,
한 서버에 무리가 가지 않도록 부하를 분담 할 수 있다.
EC2 에서는 Auto Scaling 그룹이 있으며 ECS 클러스터 생성시 지정해줄 수도 있다. (최소 갯수, 최대 갯수 지정 가능)
스케일 아웃 기준은 로드밸런서 부하량, CPU 사용량, 메모리 사용량 등이 있으며 필요에 따라 선택할 수 있다.
3. MSA(Micro Service Architecture)의 개념을 설명하라.
마이크로서비스란 작고, 독립적으로 배포 가능한 각각의 기능을 수행하는 서비스이다.
마이크로서비스로 독립적으로 실행되는 각 서비스들은 서로의 서비스에 영향을 끼치지 않으며,
각각 배포 및 관리가 가능하고, 각각 다른 기술 스택(개발 언어, 데이터베이스 등)이 사용 가능하다.
리눅스 컨테이너 기술이 핵심이다.
4. MSA의 장점은 무엇인가? 기존 방식에 비해 어떤 Benefit을 가져올 수 있는가? 그리고 그에 따른 단점이나 리스크가 있는가?
각각 독립적으로 실행되는 서비스를 통해, 하나의 서비스가 장애를 일으켜도 SPoF(단일 장애점)을 회피 할 수 있고,
동일한 서비스를 컨테이너화하여 여러 환경에 배포 및 운영을 하며 고가용성을 유지 할 수 있다는 장점이 있다.
또한 서비스 별로 필요한 기술 스택을 달리 할 수 있다.
대표적인 단점으로는 수많은 마이크로 서비스를 관리할 수 있는 운영 도구가 있다지만, 실제로 서비스 간 통신이라던지 실제 요구 사항에 맞는 서비스를 분할하며 아키텍쳐를 설계한다는 게 단점인 것 같다. 또한 서비스 아키텍처에 대해 러닝커브가 높고 많아지면 많아질수록 전체 서비스에 대한 복잡도가 올라갈 수 있다.
5. 컨테이너란 무엇인지 설명하라.
소프트웨어 서비스를 실행하는 데 있어 , 필요한 특정 버전의 프로그래밍 언어 런타임 및 라이브러리와 같은 종속성과 애플리케이션 코드를 함께 포함하는 경량 패키지라고 할 수 있다.
운영체제 수준에서 호스트 OS의 커널을 통해 CPU, 메모리, 스토리지, 네트워크 리소스를 호스트 환경의 프로세스와 동일하게 취급당하며
또한 실행 환경에서 애플리케이션을 추상화 할 수 있는 논리 패키징 메커니즘을 제공한다.
6. 컨테이너를 위한 운영 환경에는 어떠한 것들이 있는가? 가장 많이 사용되는 것은 무엇인가?
대표적인 컨테이너 오케스트레이션 도구로는 도커 스웜, 쿠버네티스 , 도커 컴포즈가 있으며, 가장 많이 사용되는 것은 쿠버네티스라 할 수 있다.
7. 쿠버네티스가 가장 선호되는 이유가 무엇이라고 생각하는가?
아무래도 쿠버네티스는 주요 클라우드 서비스에서 매니지드 서비스 형태로 제공되는 게 큰 이유인 것 같다.
명령행 도구로 명령을 입력하기만 해도 여러 대의 노드를 갖춘 쿠버네티스 클러스터를 즉석에서 생성할 수 있기 때문이고, 또한 노드 역할을 하는 가상 머신의 관리까지 맡아준다. 또한 쿠버네티스에선 스웜과 달리 세세하게 설정할 수 있는 기능이 많기 때문이기도 하다. 예를 들어 블루-그린 배포나 자동 스케일링, 역할 기반 접근 제어 같은 기능을 쿠버네티스에 쉽게 적용이 가능하다.
8. 쿠버네티스 클러스터의 기본 아키텍처에 대해 설명하라.
마스터 노드와 워커 노드로 구성되며 마스터 노드는 배포할 서비스 스케줄링, 워커 노드 갯수 관리, API 엔드 포인트 제공 등을 담당하며,
워커 노드는 여러 개의 파드로 구성되며 각 파드는 여러 서버로 구성될 수 있고 각각 여러 컨테이너들을 함께 실행이 가능하다.
9. 모니터링 툴을 사용해본 적이 있는가? 있다면 그에 관해 설명하라.
오픈소스 APM으로 핀포인트를 사용해본 경험이 있다. 핀포인트는 애플리케이션의 코드에 직접 수정을 하지 않고, BCI ( Byte Code Instrumentation ) in Java로 클래스 로드 시점에 애플리케이션 코드를 가로채 성능 정보와 분산 트랜잭션 추적에 필요한 코드를 주입하는 것이었다. 그렇게 추적된 트랜잭션은 요청이 들어올 시 실시간으로 확인이 가능하며, 특정한 시간대에 모든 요청들의 샘플링도 할 수 있을 뿐더러, 콜스택을 자세하게 볼 수 있는것이 흥미로웠다.
10. 쿠버네티스에서 Auto Scaling의 원리에 대해 설명하라.
애플리케이션의 부하나 트래픽 증가에 따라 인스턴스 수를 동적으로 조절한다. 쿠버네티스는 주어진 조건으로 각 파드의 리소스 사용량을 모니터링하고 필요한 경우 파드의 복제본 수를 조절한다. 예를 들어 CPU 사용률이 높아지면 쿠버네티스 컨트롤 플레인은 파드의 복제본 수를 늘려서 자동으로 부하를 분산시켜준다. 이때 , 새로운 파드를 생성하거나 기존 파드를 삭제 할 수도 있다.
컨트롤 플레인이 스케일링 결정을 내린 후, 각 연결된 워커노드에 파드의 크기를 조절하는 작업을 수행한다.
프로젝트를 여러 개 해보며, 본인을 포함한 팀원들이 배포된 프로젝트에 대한 모니터링이 잘 되지 않아,
수많은 트러블 슈팅에 많은 난항이 있었다.
예를 들어, (배포 환경에서) 특정 부분에서 오류가 발생해 서비스가 잘 동작하지 않는 상황에서,
개발자 입장에서는 어디서 어떤 함수가 오류를 일으켰는지,
DB의 문제인지 코드의 문제인지..등등을 단번에 파악하기란 매우 어려운 일이다
또한, 향후 진행하게 될 프로젝트에 대해(BtoB든 BtoC) 효과적인 모니터링 시스템이 있으면 좋겠다는 생각을 누구나가 했을 터.
그러던 중,,, 네이버에서 만든 모니터링 오픈 소스 핀포인트를 발견 했으며 이는 꽤나 엄청났다.
핀포인트 ?
위와 같이분산환경에서 애플리케이션 모니터링에 최적화된 기능이 많아 매우 유용하게 사용이 가능하다.
응답 코드는 물론Response가 얼마나 걸렸는지, 자세히 까보면어느 함수가 불려서 어떤 쿼리가 실행되었는지도 자세하게 나온다.
실제 모니터링 화면
Java 분산 서비스 및 시스템의 지속적인 성능 분석을 제공하며, 오류 발생 가능성에 대한 진단과 추적을 지원하는 플랫폼 서비스.
분산 애플리케이션의 트랜잭션 분석
지금은 애플리케이션이 하나라 대시보드에 하나만 보이지만, 프로젝트와 핀포인트 에이전트를 동시에 구동할 때 ( java, -javaagent:핀포인트에이전트가 설치된 경로, DdpointApplicationName=애플리케이션이름, DdpointApplicationId=에이전트id, -jar, 애플리케이션.jar)
위의 명령어의 에이전트 id로 애플리케이션이 여러 서버에 분산 되어 있을 때
애플리케이션이름으로 등록된 에이전트 id를 통해 여러 서버에 있는 애플리케이션도 동시에 확인이 가능함
Deep Dive..
핀포인트 개발 동기
과거 인터넷 서비스는 사용자가 적음과 동시에, 구조 자체가 단순했었다.
2계층(웹 서버 + 데이터베이스) 또는 3계층(웹 서버, 웹 애플리케이션 서버, 데이터베이스)로 구성해 서비스를 운영이 가능했음.
하지만 인터넷 서비스가 발전하면서 3계층을 넘어 n계층 (multitier) 아키텍처로 변경 되어지며, 마이크로서비스 형식의 아키텍처는 이제 현실이 되어가고 있었다.
n계층 아키텍처로 변화함에 따라 시스템의 복잡도도 덩달아 증가하며, 장애나 성능 문제가 발생했을 때 해결이 어려워졌다.
따라서 이러한 문제점을 해결하기 위해 네이버에서는 n계층 아키텍처를 효과적으로 추적할 수 있는 새로운 플랫폼을 개발하기로 하였다.
핀포인트 특징
분산된 애플리케이션의 메시지를 추적할 수 있는 분산 트랜잭션 추적
애플리케이션 구성 자동 파악해서 대시보드에 뿌려줌
대규모 서버군을 지원할 수 있는 수평 확장성
뛰어난 가시성으로 문제 발생 지점과 병목 구간을 쉽게 발견
분산 트랜잭션 추적 방법
RPC …?
💡 Remote Procedure Call(원격 프로시저 호출)의 약자로,
별도의 원격 제어를 위한 코딩 없이 다른 주소 공간에서 “함수나 프로시저”를 실행할 수 하는 프로세스 간 통신 기술을 말한다.
→ 프로그래머는 함수가 프로그램이 존재하는 로컬 위치에 있든, 원격 위치에 있든 상관없이 동일한 기능을 수행할 수 있음을 의미.
일반적으로 프로세스는 자신의 주소공간 안에 존재하는 함수만 호출하여 실행이 가능함.
그러나, RPC의 경우 자신과 다른 주소 공간에서 동작하는 프로세스의 함수를 실행할 수 있게 해주는데,
이는 네트워크를 통한 메시징을 수행하기 때문.
⇒ MSA 구조의 서비스를 만들 때, 언어나 환경에 구애받지 않고, 비즈니스 로직을 개발하는데 집중할 수 있다 !
Google Dapper의 분산 트랜잭션 추적 방법
분산 트랜잭션 추적의 핵심은 그림처럼 Node1 에서 Node 2로 메시지를 전송했을 때, 분산된 Node1과 Node 2가 처리한 메시지의 관계를 찾아내는 것 !!
그러나 , 메시지의 관계를 찾을 때 어려운 점은 Node1이 보낸 N개의 메시지와 Node 2에 도착한 N개의 메시지를 보고,
메시지 간의 관계를 엮을 수 있는 방법이 없다는 것이다.
즉, Node1에서 X번째 메시지를 보냈을때, Node 2가 받은 N개의 메시지 중 X번째 메시지를 선택할 수가 없다.
TCP 프로토콜이나 운영체제의 수준에서 추적하려 했지만 프로토콜마다 별도로 구현해야 해 복잡도가 높고 성능이 좋지 않았다고 한다.
=> 고질적인 문제인 메시지를 정확하게 추적 해결을 하지 못했다고 한다.
하지만 Google Dapper팀은 이 문제를 간단한 방법으로 해결했다.
메시지 전송 시 애플리케이션 수준에서 메시지를 엮을 수 있는 태그를 추가 한것이다.
HTTP를 예로 들면, HTTP 요청 전송 시, HTTP 헤더에 메시지 태그 정보를 넣고 , 이 정보를 메시지 간의 연결 고리로 활용해 메시지를 추적한다.
TransacionId(TxId) : 분산된 노드를 거쳐 다니는 메시지의 아이디로, 전체 서버군에서 중복되지 않아야 함.
SpanId : RPC 메시지를 받았을 때 처리되는 작업의 아이디를 정의함. RPC가 노드에 도착했을 때 생성.
ParentSpanId : 호출한 부모의 SpanId를 나타냄
구성 요소
Pinpoint Agent
애플리케이션의 모니터링 정보를 Collector로 전달
현재 프로젝트에선 해당 Agent는 백엔드 서버 컨테이너가 돌아가는 EC2 서버에 위치한다.
EC2에 pinpoint Agent + Spring Project 요렇게 있는 셈.
Pinpoint Collector
위의 Agent 서버에서 받은 정보를 HBase란 곳에 적재 한다.
Pinpoint는 코드 수준의 정보를 추적하기 때문에 트래픽이 많으면 많을 수록 데이터의 양이 폭발적으로 증가한다는 단점이 있다.
그래서 핀포인트는 이 정보들을 Hbase에 담아서 활용한다.
Hbase ? 구글의 BigTable을 기반으로 발전한 NoSQL 오픈 소스.
실시간 읽기/쓰기 기능을 제공한다고 한다.
강력하게 일관된 읽기/쓰기고속 카운터 집계와 같은 작업에 매우 적합.
현재 프로젝트에서 해당 Collector는 인바운드 규칙이 좀 특이하단 걸 볼 수 있는데, 이는 Agent에서 Collector로 데이터를 보내는 포트가 8000 ~ 9999 번대이기 때문.
Pinpoint Web
적재된 데이터를 웹으로 노출하여 모니터링 제공
문제점
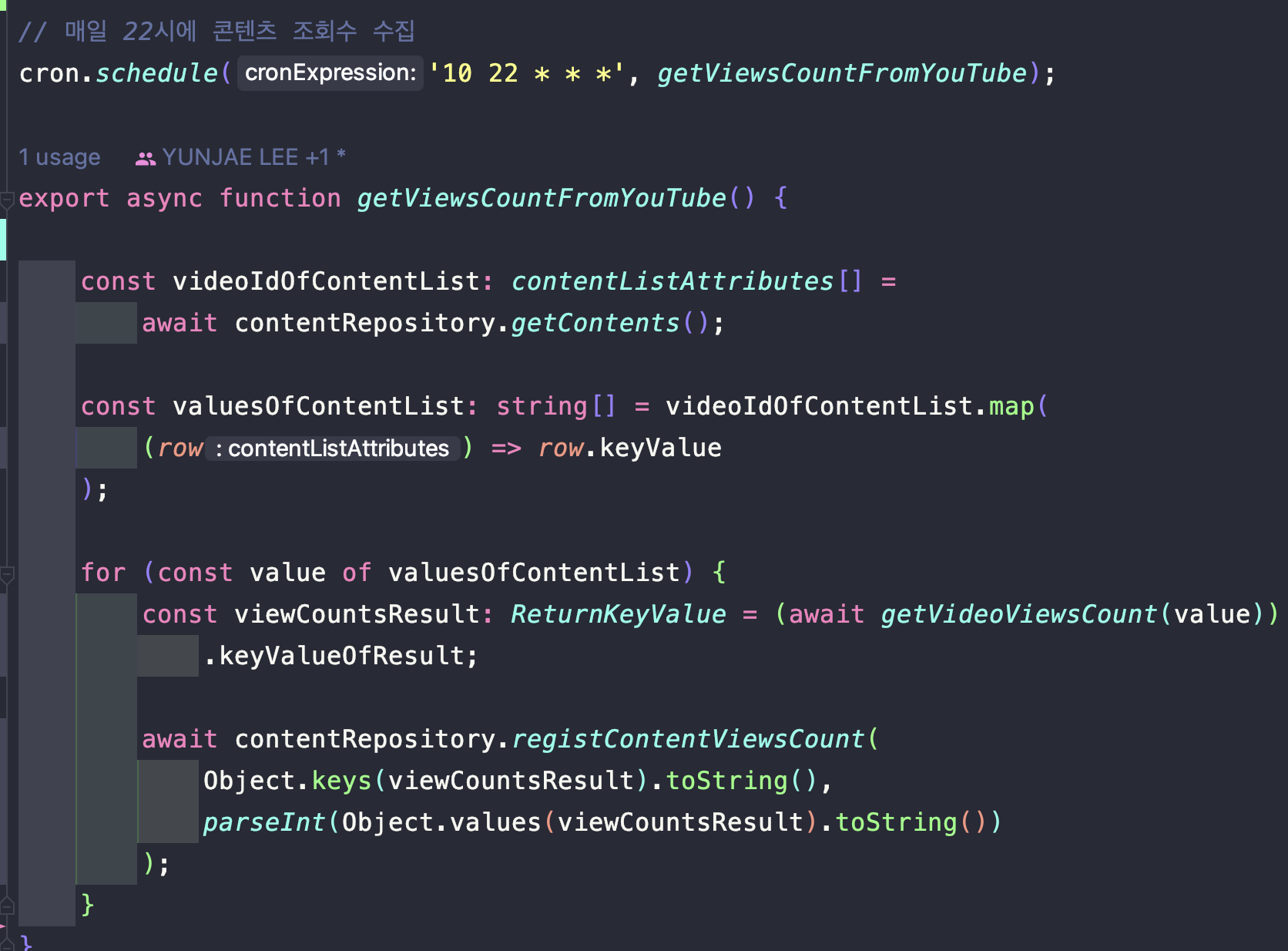
프로젝트가 위치한 서버는 Serverless 컴퓨터 형태인 Fargate 방식임.
EC2 백엔드 서버에 Agent를 설치를 해야 하는데, 접속할 서버가 없음 .
Fargate 컴퓨팅 서비스는 그냥 컴퓨터 사양 이것저것 안 만들고 그냥 실행할 도커 이미지만 있으면 실행할 수 있도록 설계 되어 있음.
클러스터내 지원 컴퓨팅
현재 프로젝트 AWS ECS 클러스터는 이런 상황을 염두에 두지 않고, Fargate 컴퓨팅만 실행하도록 되어 있었음
고로, 기존 클러스터를 전부 다 삭제 하고 새로운 클러스터와 EC2 서버를 입맞에 맞게 생성해야함. → 프로젝트 규모에 맞게 …
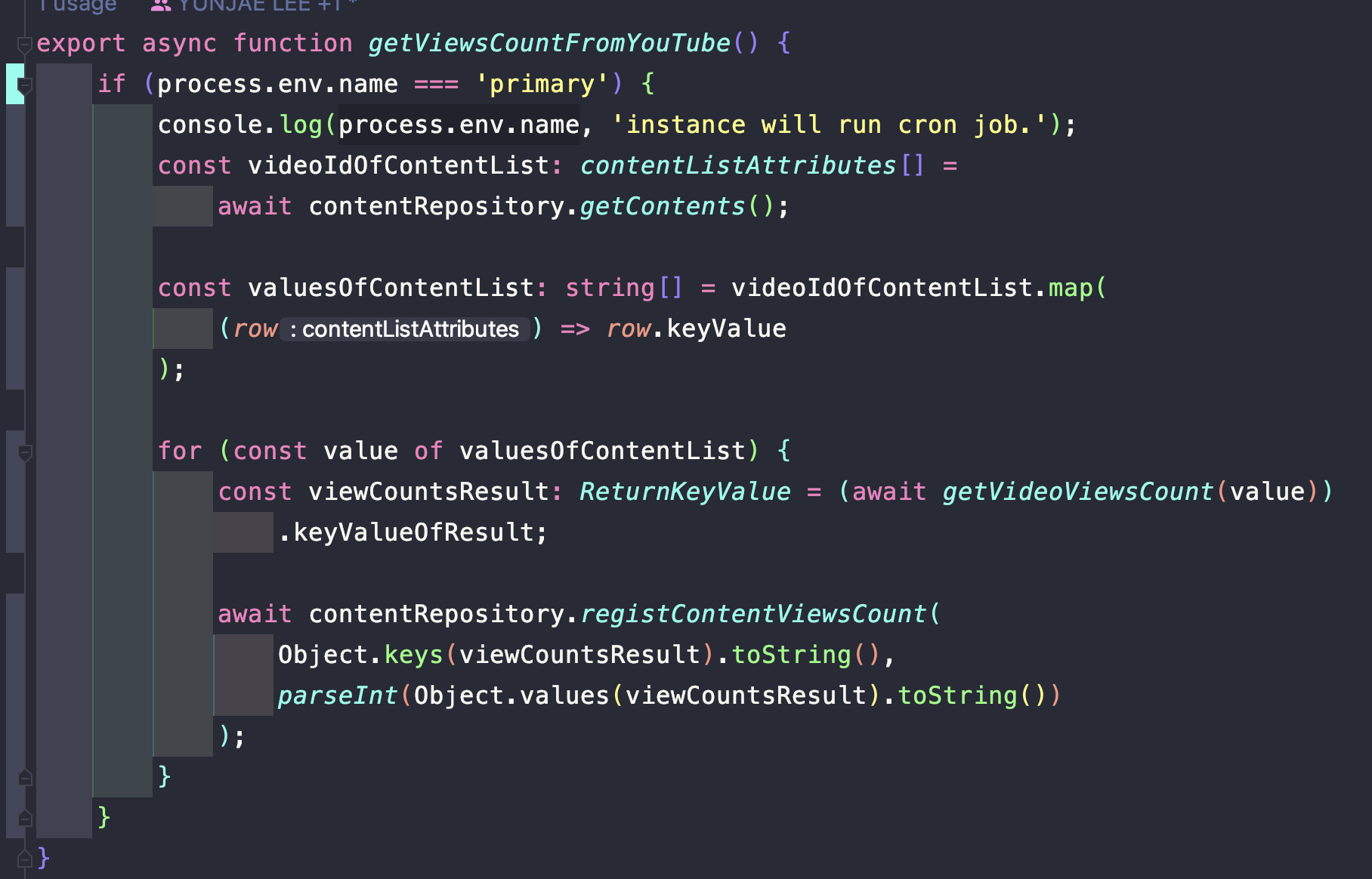
도커 기반 환경에서 Pinpoint Agent 설치 …
위에서 나열한 문제점은 어찌저찌 해결이 가능했다.
기존 클러스터를 삭제하고 Fargate 컴퓨팅과 EC2 컴퓨팅이 둘 다 가능한 새로운 클러스터를 만들었다.
또한 GitActions에서 우리 프로젝트를 빌드하고 서버에 전달해줄 때는 amd64 기반 이미지라
해당 CPU 아키텍처에 맞춰 다시 만들어 주었음
GitActions에서 이미지를 빌드 하고, AWS ECR에 푸쉬하고 EC2 서버에 배포로 변경
여기서 제일 큰 문제가 발생하는데
처음에는 핀포인트 에이전트(수집 서버에 전달할 에이전트) 이미지 레이어를 추가시켜
애플리케이션의 이미지를 빌드하는 과정에 이를 넣는 방식을 사용하려 했다.
이렇게 한다면 그냥 도커 이미지만 있어도 알아서 핀포인트 에이전트와 애플리케이션이 통째로 포함된 컨테이너가 실행될테니 말이다.
하지만 위의 방법은 이미지를 빌드 하는데 너무 많은 시간이 걸렸고,
이미지의 크기도 너무 증가하여
결과적으로 배포하는 시간이 오래 늘어나게 되었다.
모니터링 데이터 누적 수집 불가
핀포인트가 배포할때마다 이미지 내부에 설치 됨.
배포가 일어날때마다 모니터링 데이터가 아예 초기화가 되버림
백엔드 서버가 돌아가는 환경에 자체적으로 설정해놓는게 아닌 이상 데이터를 누적 할 수 없음.
해결방안 - 도커 바인드 마운트
바인드 마운트란 ?
호스트의 스토리지를 컨테이너에 직접적으로 연결할 수 있는 방법.
`바인드 마운트`는 호스트 컴퓨터 파일 시스템의 디렉터리를 컨테이너 파일 시스템의 디렉터리로 만든다.
컨테이너 입장에서는 그냥 평범한 디렉터리에 불과하지만,
도커를 사용하는 입장에서는 컨테이너가 호스트 컴퓨터의 파일에 직접 접근도 가능하고,
그 반대도 가능하다.
- 바인드 마운트를 사용하면 호스트 컴퓨터의 파일 시스템을 명시적으로 지정해서 컨테이너 데이터로 쓸 수 있다.
- 속도 면에서 뛰어난 SSD 디스크, 네트워크상에서 사용하는 분산 스토리지까지
- 호스트 컴퓨터에서 접근 가능한 파일 시스템이라면 무엇이든 컨테이너에서도 사용할 수 있다.
따라서, 호스트에 설치된 핀포인트 에이전트를 컨테이너가 중단되거나,
실행될 때 영속성을 유지(호스트 서버의 핀포인트 에이전트 관련 환경 설정 파일 등..) 할 수 있어야 했기 때문에
컨테이너의 바인드 마운트 기능을 사용하기로 했으며 곧바로 이를 적용하였다.
프로젝트가 포함된 이미지가 컨테이너에서 실행 시, 호스트에 설치되어 있는 핀포인트 에이전트 경로를 마운트 시킴
해당 폴더에는 핀포인트 에이전트를 실행하기 위한 .jar 파일과 config 파일 등이 있다
로컬에 있는 /home/ec2-user/pinpoint-agent 를 같이 사용하게 됨
볼륨이름을 pinpoint-agent로 설정해주고, 해당 볼륨을 컨테이너 내부에 /app/pinpoint-agent에 생성하도록 했다.
요렇게 실행시점에 실행 서버 환경의 폴더를 마운트를 시켜놓으면 ,
컨테이너 실행 시점에서 위의 명령어들을 사용해 웹 애플리케이션과 핀포인트 에이전트를 같이 구동하게 된다.
# 0부터 9까지의 수를 포함하는 리스트
array = [i for i in range(10)]
# range라는 함수는 0부터 9까지 i가 순회 할 수 있도록 해줌
# i라는 변수가 0부터 9까지 증가를 할 때마다, 그 i 값을 원소로 설정해서 리스트를 만듬
print(array)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
이렇게 유용한 게 있었다니…
# 0 부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i & 2 == 1]
#0 부터 19까지 홀수만 출력 됨
print(array)
# 1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [i * i for i in range(1,10)]
# i라는 변수는 1부터 9까지 증가하며 i 값들을 제곱해서 새로운 리스트를 만듬
또한, 리스트 컴프리헨션은 2차원 리스트를 초기화 할 때 효과적으로 사용이 가능
특히 N X M 크기의 2차원 리스트를 한 번에 초기화 해야 할 때 매우 유용함.
좋은 예시 : array = [[0] * m for _ in range(10)] → 반복 될 때 마다, m (열) 크기 만큼 리스트의 원소를 설정
n 번 반복을 할 때마다, 배열(가로) 길이가 m인 리스트(내용물이 0)를 생성함
언더바는 언제 사용 하는가?
파이썬에서는 반복을 수행하되, 반복을 위한 변수의 값을 무시하고자 할때 언더바(_)를 자주 사용한다고 한다.
# 1부터 9까지의 자연수를 더하기
summary = 0
for i in range(1, 10):
summary += i
# 반복문을 수행하며 , i값을 더하기 위해
# i 값이 필요하니 변수를 만듦
# Hello World를 5번 출력
for _ in range(5):
print("Hello World")
# 반복문을 돌며 특정한 값이 필요없고,
# 그냥 반복만 하고 싶을 경우이니 _
# 언더바 사용
튜플 자료형
튜플 자료형은 리스트와 유사하지만 다음과 같은 문법적 차이가 있다.
튜플은 한 번 선언된 값을 변경할 수 없다.
리스트는 대괄호 [] 를 이용하지만, 튜플은 소괄호 () 를 이용한다.
튜플은 리스트에 비해 상대적으로 공간 효율적이다.
# 튜플 사용 예제
a = (1, 2, 3, 4, 5, 6, 7, 8, 9)
# 네 번째 원소만 출력
print(a[3])
# 두 번째 원소부터 네 번째 원소까지
print(a[1:4])
튜플내의 값을 변경하려 한다면( ex : a[2] = 7),
tuple 객체의 값은 Immutable(불변)이니 변경하지 못한다고 에러가 뜸
튜플을 사용하면 좋은 경우
서로 다른 성질의 데이터를 묶어서 관리해야 할 때
최단 경로 알고리즘에서는 (비용, 노드 번호)의 형태로 튜플 자료형을 자주 사용함
예를 들어 , 학생의 학번, 성적과 같이 다른 성질의 데이터를 묶을 때. 다양한 정보를 포함 가능
데이터의 나열을 해싱의 키 값으로 사용해야 할 때
튜플은 변경이 불가능하므로 리스트와 다르게 키 값으로 사용될 수 있다.
리스트보다 메모리를 효율적으로 사용해야 할 때 .
집합 자료형
집합은 다음과 같은 특징이 있다.
중복을 허용하지 않음
순서가 없음
집합은 리스트 혹은 문자열을 이용해서 초기화 할 수 있다.
이때 set() 함수를 이용함.
혹은 중괄호안에 각 원소를 콤마(,)를 기준으로 구분하여 삽입함으로써 초기화 할 수 있다.
데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리할 수 있다.
# 집합 자료형 초기화 방법 1
data = set([1, 1, 2, 3, 4, 5 ]) -> 중복이 제거 된 후, 집합 자료형으로 됨.
# 집합 자료형 초기화 방법 2
data = {1, 1, 2, 3, 4, 4, 5}
# 집합 자료형으 ㅣ연산
a = {1, 2, 3, 4, 5}
b = {3, 4, 5, 6, 7}
# 합집합
print(a | b)
# {1, 2, 3, 4, 5, 6, 7}
# 교집합
print(a&b)
# {3, 4, 5}
# 차집합
print( a - b)
# {1, 2}
기본 입출력
input() 함수는 한 줄의 문자열을 입력 받는 함수.
map() 함수는 리스트의 모든 원소에 각각 특정한 함수를 적용할 때 사용.
# 공백을 기준으로 구분된 데이터를 입력 받을 때는 다음과 같이 사용
list(map(int, input().split()))
# 공백을 기준으로 구분된 데이터의 개수가 많지 않다면, 단순히 다음과 같이 사용
a, b, c = map(int, input().split()) -> 바로 a, b, c 변수에 할당 가능
빠르게 입력 받기
사용자로부터 입력을 최대한 빠르게 받아야 하는 경우가 있음
파이썬의 경우 sys 라이브러리에 정의돼 있는 sys.stdin.readline() 메서드를 이용함.
단 입력 후 엔터가 줄 바꿈 기호로 입력되므로 rsstrip() 메서드를 함께 사용함.
조건문과 반복문
조건문에서 아무것도 처리하고 싶지 않을때 pass 키워드를 사용한다고한다.
예시 ) 디버깅 과정에서 일단 조건문의 형태만 만들어 놓고 조건문을 처리하는 부분은 비워놓고 싶은 경우
score = 85
if score >= 80:
pass # 나중에 작성할 소스코드
else:
print('성적이 80점 미만입니다')
print('프로그램을 종료합니다')
# 결과 : 프로그램을 종료합니다
# 파이썬 조건문 내에서으 ㅣ부등식
x = 15
if 0 < x < 20:
print()
# 요런것도 가능하다구 한당 !
람다 표현식
람다 표현식을 이용하면 함수 간단하게 작성할 수 있음
특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다는 점이 특징임.
# 람다 표현식으로 구현한 두 매개변수의 합 구하기
# 이름 없는 함수라고도 불림 (ㄷ ㄷ 처음 앎)
print((lambda a, b : a + b)(3,7))
# 예시: 내장 함수에서 자주 사용되는 람다 함수
array = [('홍길동', 50), ('이순신', 32)]
# 각 원소들이 튜플 형태로 구성되어 있음
print(sorted(array, key=lambda x : x[1])
# 어떠한 튜플이나 리스트와 같은 원소가 있을때, 얘의 두번째 (여기서는 점수 -> 1번째 값)
# 튜플의 2번째 값을 기준으로 정렳할 수 있음
# 정렬 기준 (key 속성)를 람다함수를 사용함.
# 여러 개의 리스트에 적용
list1 = [1,2,3,4,5]
list2 = [6,7,8,9,10]
result = map(lambda a, b: a+b, list1, list2)
# map 함수는 각각의 원소에 대해 어떠한 함수를 적용하는 것임
# 따라서 list1과 list2의 각각의 원소를 더함
# 각각의 순서에 맞는 값끼리 더함 -> 1 +6, 2+7, 3+8 ...