안녕하세요 이번 포스팅에서는 수십 개의 크롤러들을 도커라이징하며 겪었던 문제 및 문제 해결을 했던 과정을 소개 시켜 드리려고 합니다.
( 그 전부터 정리해야지.. 정리해야지.. 하고 미루다가 이제서야 하게 됐네요)
그전에 왜 수십 개의 크롤러들을 도커라이징 고려를 했는지에 대해 말씀드리려 합니다.
우선, 기존 사내 서버실 데스크탑에서 주기적으로 실행되는 크롤러 프로세스들은
- 로컬 개발 환경과 배포 서버 환경의 차이로 인한 각종 에러로 인해, 해당 에러를 처리하는 데에만 꽤나 유의미한 시간이 들었습니다.
- 프로세스가 다운 될 정도의 에러가 발생 시 즉각적으로 대응하지 못하는 점.
(해당 상황 발생 시, 대부분은 프로세스를 다시 실행 시키는 정도의 수준으로 대응이 가능했습니다.)
- 크롤러 내부 로직 수정 시, 수동 배포와 같은 반복적인 작업.
위 사항을 비롯해 기존부터 크롤러 관리의 어려움을 느끼고 있어서 해당 부분을 팀원분들과 논의를 마친 후, 도커라이징을 하기로 결정하게 되었습니다.
크롤러 "공통" Dockerfile의 대략적인 내용은 아래와 같습니다
# Base image
FROM python:3.9
# Set the working directory in the container
WORKDIR /app
RUN apt-get update && apt-get install -y \
chromium \
chromium-driver
# Copy the project files to the working directory
COPY . .
# Install required libraries
RUN pip install -r requirements.txt
# Set the entrypoint command
ENTRYPOINT ["/bin/bash", "-c", "exec \"$@\"", "--"]
ENTRYPOINT만 작성한 이유는 해당 도커 이미지의 진입점을 /bin/bash로 설정해놓은 다음
- 뒤에 오는 CMD 명령을 인자로 받는 다는 뜻이며 , 이는 곧 컨테이너 별로 다르게 실행될 스크립트를 지정해줌으로써 컨테이너 별로 공통 이미지를 가지며 서로 다르게 실행시키기 위함입니다.
- 컨테이너가 실행될때의 명령을 컨테이너마다 각기 달리 줘야 하기 때문입니다.
크롤러 별 도커 컴포즈 구성은 대략적인 내용은 아래와 같습니다.
// 도커 컴포즈의 버전을 명시
version: '2'
services:
crawler1:
container_name: crawler1
build: .
command: python3 -u main.py crawler1
network_mode: host
craler2:
container_name: crawler2
build: .
command: python3 -u main.py crawler2
network_mode: host
...
각 서비스의 컨테이너 별 command는 단일 도커 파일에서 봤을때 다음과 같은 효과가 생기게 됩니다.
- ENTRYPOINT ["/bin/bash", "-c", "exec \\"$@\\"", "--"]
- CMD [”python3”, "-u", "main.py", “crawler1”]
여기서 한가지 궁금점이 생기실 수도 있는데 만약, ENTRYPOINT만 정의되어 있고, 도커 컴포즈 실행시 Command 지시자가 없다면 어떻게 될까?
해당 물음에 대한 자세한 포스팅은 아래 링크를 참조하시면 좋을 것 같습니다.
https://www.popit.kr/%EA%B0%9C%EB%B0%9C%EC%9E%90%EA%B0%80-%EC%B2%98%EC%9D%8C-docker-%EC%A0%91%ED%95%A0%EB%95%8C-%EC%98%A4%EB%8A%94-%EB%A9%98%EB%B6%95-%EB%AA%87%EA%B0%80%EC%A7%80/
요약하자면, 도커 컨테이너는 가상머신과 같이 하나의 온전한 서버를 제공하는 것이 아닌, 명령을 실행하는 환경만 제공하고, 그 명령을 실행할 뿐입니다. ( 이 이야기에 대해선 다음번에 좀 더 자세히 다루도록 하겠습니다. )
AWS EC2 환경에서의 컨테이너
- 크롤러 EC2 인스턴스(우분투 리눅스)에는 도커만 설치하고, 크롤러 이미지는 따로 도커 허브를 이용하진 않았습니다.
(테스트 목적이기도 했고, 퍼블릭한 공간에 이미지를 노출하기가 꺼렸습니다. + 프라이빗은 유료..) - 버전 관리를 위해 git 으로 필요한 소스코드 파일과 도커 파일, 도커 컴포즈 파일만 호스트에서 이미지를 빌드하고 컨테이너를 실행하게 했습니다.
- 성공적으로 첫 단계를 밟았다고 생각했으나 문제가 생기게 됩니다.
DB ETIMEDOUT 문제
- EC2 인스턴스 내의 프로젝트 폴더에서 직접 코드를 실행했을 때는 잘 되었지만
- 도커 컴포즈로 컨테이너를 실행시켰을 때, 로그에 DB ETIMEDOUT이라는 에러가 발생하여, 컨테이너가 종료되는 에러가 발생했습니다.
- 당시의 문제점 파악으로는, 우선 네트워크 문제를 고려했습니다. ( 해당 문제가 아닐 수도 있습니다. )
- 정리하자면, EC2 인스턴스에서의 크롤러 프로세스는 호스트 네트워크를 사용해 DB와 연결을 하고 데이터를 받아와 크롤링을 합니다.
- 하지만, 컨테이너는 도커가 부여해준 가상 인터페이스를 가지고 외부로 나가 DB와 연결을 하기에 모종의 이유로 타임아웃이 발생할거라 생각했습니다.
💡 Docker 네트워크는 bridge, host, overlay 등 목적에 따라 다양한 종류의 네트워크 드라이버(driver)를 지원하는데요.
- bridge 네트워크는 하나의 호스트 컴퓨터 내에서 여러 컨테이너들이 서로 소통할 수 있도록 해줍니다.
- host 네트워크는 컨터이너를 호스트 컴퓨터와 동일한 네트워크에서 컨테이너를 돌리기 위해서 사용됩니다.
- overlay 네트워크는 여러 호스트에 분산되어 돌아가는 컨테이너들 간에 네트워킹을 위해서 사용됩니다.
따라서, EC2 인스턴스의 네트워크 인터페이스를 그대로 활용하기 위해 위의 도커 컴포즈 파일의 네트워크 모드를 호스트로 설정해주었습니다.
컨테이너 헬스 체크 과정
- 호스트 네트워크 모드를 사용해 성공적으로 크롤러들을 실행시키는데 성공했습니다.
- 그러나, 크롤러가 작동할수록 서버의 CPU 사용량(4vCPU, 8GB)이 무지막지하게 늘어났고(아마 브라우저를 계속 생성해서 그런 거 같음)
- 추후에 생각난건데, 네트워크 I/O 부분도 고려하지 못한게 아쉽다고 생각이 드네요
- 그 후엔 컨테이너는 정상 실행 상태지만 내부에서는 파이썬 프로세스가 exit가 되어버리며 크롤링이 되지 않는 상황이 발생했습니다.
- 따라서 적절한 헬스체크 방식이 필요했으며 헬스체크 실패 시 , 컨테이너를 다시 띄우려고 시도 했습니다.
CloudWatch
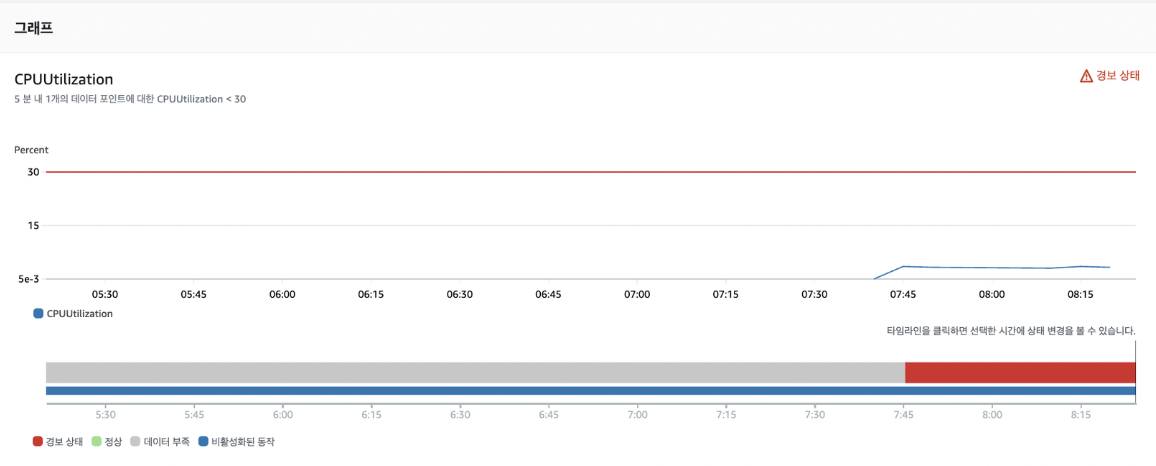
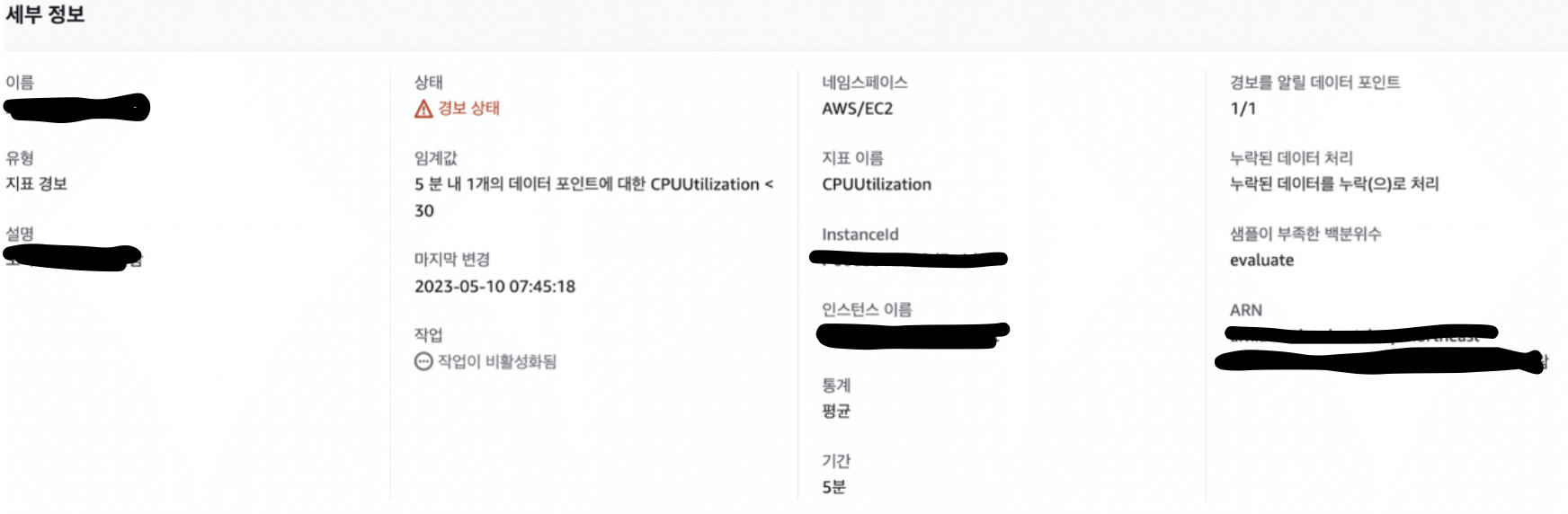
- 크롤러 컨테이너들을 실행하고 CPU 사용량을 관측한 결과, 평균 CPU 사용률이 7~80%를 왔다갔다 했었습니다.
- 이후로, 파이썬 프로세스가 컨테이너 내부에서 종료 됐을 시에는 CPU 사용률이 2~30%를 왔다갔다 했었습니다.
- 그래서 위 지표를 토대로 CloudWatch의 CPU 사용률이 30%보다 아래일 때, 크롤러 컨테이너들이 종료됐다고 판단하고,
이것을 트리거 삼아 AWS SNS에 이벤트를 게시하게 하였습니다.
SimpleNotificationService ( SNS )
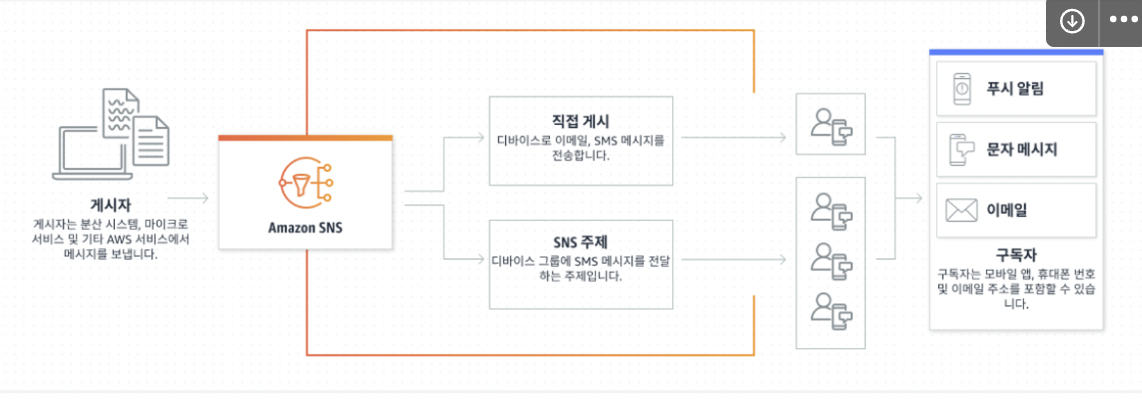
- 위 서비스의 새로운 주제를 생성해, 엔드 포인트를 람다 함수로 설정하여, (나름의) 헬스 체크 실패 시 다시 컨테이너를 띄울 수 있는 방식을 택했습니다.
AWS Lambda
Layers 구성
- 처음 람다 함수를 실행할 때, 필요한 모듈을 import를 했어야 했는데
- docker, slack, 인스턴스에 명령을 전달하기 위해 인스턴스와 연결하는 boto3 모듈 가 import가 되지 않았습니다.
- 람다 공식 문서를 잘 살펴보니 함수를 실행하기 위한 특정 모듈들은 직접 .zip파일로 만들어서 업로드를 해줘야 동작을 할 수 있었습니다.
- 그래서 필요한 모듈들을 직접 pip3를 이용해 설치하고,
- 모듈들이 설치된 파일을 .zip파일로 압축시켜 신규 Layers를 생성한 뒤, 해당 Layer를 추가 해주었습니다.
Lambda 코드
import boto3
import os
import docker
import time
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
# ssm-client 계정 엑세스 키
access_key = os.environ['access_key']
secret_key = os.environ['secret_key']
region = os.environ['region']
instance_id = os.environ['instance_id']
slack_token = os.environ['slack_token']
slack_channel = os.environ['slack_channel']
container_list = os.environ['container_list']
remove_command = os.environ['remove_command']
compose_up_command = os.environ['compose_up_command']
ec2_client = boto3.client(
"ec2",
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
region_name=region
)
# ssm_client를 사용하기 위해선 해당 인스턴스에 ssm_agent가 설치 되어 있어야 하며,
# 해당 access_key를 사용자의 권한에 위의 사진과 같은 권한을 설정해주었다.
ssm_client = boto3.client(
"ssm"
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
region_name=region
)
# 도커 데몬의 기본 포트인 2375를 이용해 람다에서 명령을 실행해주기 위함
res = ec2_client.describe_instances(InstanceIds=[instance_id])
docker_host = "tcp://" + res["Reservations"][0]["Instances"][0]["PublicIpAddress"] + ":2375"
docker_client = docker.DockerClient(base_url=docker_host)
slack_client = WebClient(token=slack_token)
# 실행될 메인 람다 함수 이며 , 필수 파라미터로 event와 context가 있다.
# 이게 왜 필수냐면 트리거가 발동 되거나, 어떠한 이벤트 발생 후, 람다에 전달할때 람다에서 해당 event를 매개변수로 받아 사용해야 하기 때문.
# 근데 여기선 트리거 발생시, 실행중인 컨테이너를 전부 삭제하고 새롭게 띄우는 방식으로 설계 했기 때문에 매개변수는 따로 사용하지 않았다.
def lambda_handler(event,context):
containers = docker_client.containers.list()
send_slack_message('크롤러 중지 감ji')
message2 = '크롤러 재실행'
send_slack_message(message2)
remove_containers()
docker_compose_up()
message3 = '크롤러 재실행 complete'
send_slack_message(message3)
return
def remove_containers():
ssm_client_command(remove_command)
def docker_compose_up():
# docker-compose up 실행
project_dir = '/home/ec2-user/Overware_crawler'
compose_file = [f'{project_dir}/docker-compose.yml']
project_name = 'my_project'
options = {'--project-directory': project_dir, '--project-name': project_name}
docker_client.api.compose.up(
compose_file=compose_file,
detach=True,
options=options,
timeout=60,
)
def ssm_client_command(command):
response = ssm_client.send_command(
InstanceIds=[ec2_instance],
DocumentName="AWS-RunShellScript",
Parameters={
"commands": [command],
}
)
return
def send_slack_message(message):
try:
slack_client.chat_postMessage(channel=slack_channel, text=message)
except SlackApiError as e:
slack_client.chat_postMessage(channel=slack_channel, text=str(e))
여기까지 위에 열거한 문제 (컨테이너는 정상 실행 상태지만 내부에서는 파이썬 프로세스가 exit) 를 해결 하기 위해 했던 과정들입니다.
예전에 제가 개인적으로 따로 과정을 정리 해두었지만 글이 너무 중구난방한 상태였고, 해당 문제를 다시 복기하며 보니 개선점이 꽤나 보이네요 ..ㅎㅎㅎ;;
과정들을 겪고나니 이제서야 도커 스웜, 쿠버네티스 같은 컨테이너 오케스트레이션을 이유가 좀 더 와닿는 것 같습니다.
아쉬운 점은,
- 하나의 컨테이너가 이상이 발생해도, 정상 실행중인 컨테이너 모두를 내리고 다시 실행해야 하는 점
- 컨테이너의 내부 프로세스 상태를 확인 할 수 있는 방법을 모색하지 못한 점
- 왜 호스트의 CPU 사용률이 8~90%까지 되었는지 정확한 원인 파악을 못한 점 ( 추정 정도만 ..)
- 좀 더 Best Practice에 다가가지 못한 점
등이 있겠네요..ㅠㅠ
긴 글 읽어주셔서 감사합니다.
'Work Experience' 카테고리의 다른 글
| 좌충우돌 서비스 모니터링 핀포인트 도입기 (0) | 2023.07.25 |
|---|